Hi, I am referring code from Version 1.3 of the scheduler which can be directly accessed from this github link.
During this post, Paper refers to this paper, and Algorithm 2 (Page 6 of paper) refers to the algorithm for task departure.
The post covers the following three topics for this function:
- What this function does
- Reason behind selecting this function for implementing Algorithm 2
- Explanation of the code and design choices
Section 1: What this function does
Get_highest_ready function of a scheduler is called to get the highest ready node available to be scheduled. This function is usually called when a node which was scheduled earlier gets blocked, thus leaving the cpu empty.
Section 2: Reason for selecting this function
Following are some of the important places that _Scheduler_strong_APA_Get_highest_ready is called (and to an extent justifies our selection of the function as the place of implementation of Algorithm 2):
- In Scheduler_SMP_Schedule_highest_ready which is actually called by _Scheduler_SMP_Block. When a scheduled node changes its state to BLOCKED, the cpu that the node was executing on becomes free and thus we need to find the highest ready task which is eligible to be scheduled on that processor.
- As a result of calling _Scheduler_SMP_Set_affinity. In case a new affinity is set for a node which is already scheduled, the processor on which the node was executing on gets allocated to the highest ready node and this node changes its affinity and tries to get scheduled again by calling enqueue.
Section 3: Explaining the code
The function is divided in the following three parts:
- Initializing the data structures needed for carrying out the Algorithm 2
- Finding the highest ready reachable task
- Backtracking to schedule the highest ready task
Initializing the data structures
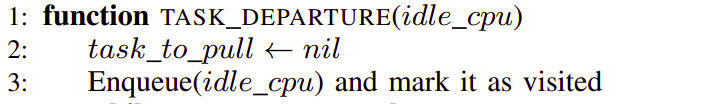
We put our cpu with no task executing on it on the queue.
uint32_t front;
uint32_t rear;
uint32_t cpu_max;
uint32_t cpu_index;
front = 0;
rear = -1;
filter_cpu = _Thread_Get_CPU( filter->user );
Struct = self->Struct;
cpu_max = _SMP_Get_processor_maximum();
for ( cpu_index = 0 ; cpu_index < cpu_max ; ++cpu_index ) {
Struct[ cpu_index ].visited = false;
}
rear = rear + 1;
Struct[ rear ].cpu = filter_cpu;
Struct[ _Per_CPU_Get_index( filter_cpu ) ].visited = true;
Corresponding link to code
We put the filter_cpu which is the cpu on which filter_node was executing. filter_node is the node which was executing earlier on the cpu which is now free. The cpu is marked visited.
Finding the highest ready task

The basic idea behind this algorithm is to find the task which can execute on the current cpu of the queue. It could be a ready task, or a task which is currently scheduled on another processor, in which case it would be preempt this cpu and we would find a task which can execute on the cpu on which it was executing to find the highest ready task and the cycle goes on.
while( front <= rear ) {
curr_CPU = Struct[ front ].cpu;
front = front + 1;
tail = _Chain_Immutable_tail( &self->All_nodes );
next = _Chain_First( &self->All_nodes );
while ( next != tail ) {
node = (Scheduler_strong_APA_Node*) STRONG_SCHEDULER_NODE_OF_CHAIN( next );
//Check if the curr_CPU is in the affinity set of the node
if (
_Processor_mask_Is_set(&node->Affinity, _Per_CPU_Get_index(curr_CPU))
) {
curr_state = _Scheduler_SMP_Node_state( &node->Base.Base );
if ( curr_state == SCHEDULER_SMP_NODE_SCHEDULED ) {
assigned_cpu = _Thread_Get_CPU( node->Base.Base.user );
index_assigned_cpu = _Per_CPU_Get_index( assigned_cpu );
if ( Struct[ index_assigned_cpu ].visited == false ) {
rear = rear + 1;
Struct[ rear ].cpu = assigned_cpu;
Struct[ index_assigned_cpu ].visited = true;
// The curr CPU of the queue invoked this node to add its CPU
// that it is executing on to the queue. So this node might get
// preempted because of the invoker curr_CPU and this curr_CPU
// is the CPU that node should preempt in case this node
// gets preempted.
node->invoker = curr_CPU;
}
}
else if ( curr_state == SCHEDULER_SMP_NODE_READY ) {
curr_priority = _Scheduler_Node_get_priority( &node->Base.Base );
curr_priority = SCHEDULER_PRIORITY_PURIFY( curr_priority );
if ( first_task == true || curr_priority < min_priority_num ) {
min_priority_num = curr_priority;
highest_ready = &node->Base.Base;
first_task = false;
//In case this task is directly reachable from thread_CPU
node->invoker = curr_CPU;
}
}
}
next = _Chain_Next( next );
}
}
return highest_ready;
Corresponding link to code
For every cpu in the queue, we go through all the nodes kept in All_nodes of our Strong APA scheduler context which keeps track of all the ready and scheduled nodes. If a node which is already scheduled has an affinity to the cpu, we put the cpu that the node is executing on in the queue and we save the current cpu in the node’s invoker value since this is the cpu that the node would preempt in case the highest ready task is found because of this node or any successor of this node ( node which came from the cpu it was executing on or the cpu that a task which has this cpu in its affinity set was executing on and so on). If the node is ready, we check if it is the highest ready node we have encountered so far and if it is, we mark it.
Backtracking to schedule the highest ready task

if ( highest_ready != filter ) {
//Backtrack on the path from
//filter_cpu to highest_ready, shifting along every task.
node = _Scheduler_strong_APA_Node_downcast( highest_ready );
if( node->invoker != filter_cpu ) {
// Highest ready is not just directly reachable from the victim cpu
// So there is need of task shifting
curr_node = &node->Base.Base;
next_node = _Thread_Scheduler_get_home_node( node->invoker->heir );
_Scheduler_SMP_Preempt(
context,
curr_node,
_Thread_Scheduler_get_home_node( node->invoker->heir ),
_Scheduler_strong_APA_Allocate_processor
);
_Scheduler_strong_APA_Move_from_ready_to_scheduled(context, curr_node);
node = _Scheduler_strong_APA_Node_downcast( next_node );
while( node->invoker != filter_cpu ){
curr_node = &node->Base.Base;
next_node = _Thread_Scheduler_get_home_node( node->invoker->heir );
_Scheduler_SMP_Preempt(
context,
curr_node,
_Thread_Scheduler_get_home_node( node->invoker->heir ),
_Scheduler_strong_APA_Allocate_processor
);
node = _Scheduler_strong_APA_Node_downcast( next_node );
}
//To save the last node so that the caller SMP_* function
//can do the allocation
curr_node = &node->Base.Base;
highest_ready = curr_node;
}
}
return highest_ready;
Corresponding link to the code
We would never encounter a case where highest_ready is NULL because of the way RTEMS scheduling works, there would always be extra idle nodes with maximum priority ready to execute.
We start from scheduling highest ready task by preempting the invoker or the cpu that the highest_ready node was called by and then we preempt the cpu which invoked the node that was executing on the cpu on which highest_ready just got executed and so on.
The first preemption is out of the loop since we need to add the highest_ready task to the list of scheduled nodes since it is now executing on its invoker cpu.
We stop just before reaching the filter_node since the SMP_function that calls the _strong_APA_Get_highest_ready uses the highest_ready node and schedules it on the cpu of filter_node.
This is it. Thanks for staying till the end!
